

Stable Diffusion(ステーブルディフュージョン)は、文章による指示文(プロンプト)を入力することで、高精細な画像を自動生成できる画像生成AIで、イギリスの Stability AI によって開発され、2022年にオープンソースとして公開されました。
拡散モデルの一種であるLatent Diffusion Modelを採用しており、ランダムなノイズから段階的に画像を構築します。写実的な写真表現からアニメ風のイラストまで幅広い表現に対応し、無料で利用できる点も特徴です。
そのため、イラスト制作やデザインなど、さまざまな分野で活用が広がっています。
この記事では、Stable Diffusionの概要、特徴、機能、利用方法について詳しく説明いたします。
Stable Diffusionの概要
Stable Diffusionは、文章(プロンプト)から画像を生成する拡散モデル(Diffusion Model)系の画像生成AIの代表格です。
大きな特徴は、画像そのものの高次元空間ではなく、画像を圧縮した潜在空間(latent space)で生成を進める「Latent Diffusion」方式を採用している点で、計算量を抑えつつ高品質な生成を狙えます。
Stable Diffusionの特徴
Stable Diffusionの特徴について紹介いたします。
特徴1:高い自由度:生成だけでなく編集が強い
Stable Diffusionは、利用するUIや導入方法によって機能の幅が大きく変わり、文章から画像を作成する生成機能(txt2img)に加え、既存画像をもとにした変換処理(img2img)や、画像の一部を書き換えるインペイント、画面外を拡張するアウトペイントといった編集作業にも対応しています。
特徴2:モデルや拡張が豊富
Stable Diffusionは利用者コミュニティが非常に活発で、目的に応じて写実系やアニメ調、背景制作に特化したモデルへ切り替えることができます。
さらに、LoRAなどによる追加学習や、Control系と呼ばれる拡張機能を組み合わせることで、表現の幅を大きく広げられます。代表例として、A1111(AUTOMATIC1111)WebUIでは、LoRAを含む多彩な機能が分かりやすく整理されています。
特徴3:進化の系譜が分かりやすい
Stable Diffusionは、SD1.xからSD2.x、さらにSDXL、SD3系へと段階的に進化してきた流れが分かりやすい点も特徴です。
中でもSDXLは、従来モデルよりも規模を拡大することで高解像度化と品質向上を実現し、テキストエンコーダを2つ採用するなどの設計が採られています。
また、Hugging Faceなどで公開されている情報によると、Stable Diffusion 3では、Diffusion Transformer(DiT系)やFlow Matchingといった新しいアーキテクチャを取り入れる方針が示されています。
Stable Diffusionの機能
Stable Diffusionの機能について紹介いたします。
機能1:生成(Text-to-Image / txt2img)
文章による指示をもとに、新しい画像を一から生成できます。また、写真調やイラスト調といった画風をはじめ、構図や被写体、背景、光源などの要素を文章で細かく指定できる点も特徴です。
機能2:変換(Image-to-Image / img2img)
既存の画像を基にして、画風を変えたり細部を加えたりするなど、全体の雰囲気を別のテイストへと変換できます。また、元画像をどの程度残すかといった影響の強さを調整できる点も特徴です。
機能3:部分編集(Inpainting / Outpainting)
Inpaintingは、画像の中で指定した部分のみを再描画する機能で、衣装の変更や背景の一部修正などに利用されます。
一方、Outpaintingは、元の画像の外側へキャンバスを広げ、その続きを生成することで、構図を拡張できる手法です。
機能4:高解像化・仕上げ(Upscale / Refiner等)
まず低い解像度で全体の構図を作成し、その後に細部の表現を段階的に作り込む手法が用いられます。特にSDXLでは、Baseモデルで画像を生成し、Refinerで仕上げを行うといった運用方法が一般的に紹介されていますが、実際の使い方は実装やUIによって異なります。
機能5:条件付けで“狙って”作る(Control系)
ポーズや輪郭、奥行き情報、線画、手描きのラフなどを条件として与えることで、意図した構図に近づけて画像を生成できます。代表的な手法としては、ControlNet系の拡張機能があり、WebUIを中心に広く活用されています。
Stable Diffusionの画像生成の流れ
Stable Diffusionの画像生成の流れを以下に説明します。
| Stable Diffusionの画像生成の流れ |
| ➊ テキスト入力 ↓ ❷ テキスト理解(CLIP) ↓ ❸ ノイズから生成(UNet) ↓ ❹ 潜在画像を復元(VAE) ↓ ❺ 完成画像 |
➊ テキスト入力(プロンプト)
ユーザーは、
・被写体(例:人物、風景)
・雰囲気(明るい、幻想的など)
・画風(写真風、アニメ調など)
といった内容を文章(プロンプト)で入力します。また、不要な要素を排除するためにネガティブプロンプトも指定できます。
❷ テキスト理解(テキストエンコーダ/CLIP)
入力された文章は、CLIP などのテキストエンコーダによって数値データ(埋め込みベクトル)に変換されます。
この段階で、
「何を・どんな雰囲気で描くか」
という意味情報がAIに伝えられます。
❸ ノイズから画像を作る(拡散過程/UNet)
ここが Stable Diffusionの中核です。
・最初はランダムなノイズ画像
・UNet というモデルが「プロンプトの意味」に沿うよう少しずつノイズを除去します。
・この処理を何十ステップも繰り返えします。
ノイズ → 形 → 構図 → 細部
という順で画像が浮かび上がってきます。
❹ 潜在画像を実画像へ変換(VAE)
Stable Diffusionの画像生成は、潜在空間(圧縮された画像表現)で行われます。
最後にVAE(変分オートエンコーダ)が潜在画像を人が見える通常の画像へ復元します。
これにより、高速かつ高品質な生成が可能になります。
❺ 画像完成
解像度、色味、光や影、質感が整えられ、最終的な画像が完成します。
同じ設定でも Seed(乱数)を変えることで、異なる画像を何枚でも生成できます。
Stable Diffusionの利用方法
Stable Diffusionは、以下の3つの方法で利用されます。
| Stable Diffusionの利用方法 |
| ➊ ローカルPCにインストールして使う ❷ Webサービス(クラウド)で使う ❸ API・ライブラリとして使う |
➊ ローカルPCにインストールして使う(定番・高自由度)
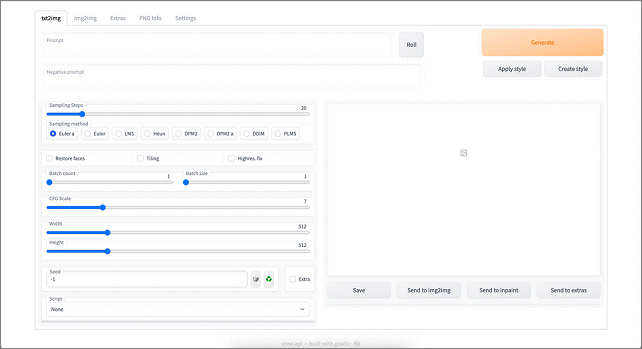
Stable Diffusion web UI
Stable Diffusionをパソコンにインストールして利用する方法は、ローカル環境で画像生成を行う点が特徴です。モデルや拡張機能を自由に追加でき、生成設定も細かく調整できます。インターネット接続に依存せず、自分専用の制作環境を構築できる点も大きな特徴です。
●メリット
・生成回数や解像度に制限がない
・モデルやLoRA、Control系拡張を自由に導入できる
・商用利用の可否を自分で管理しやすい
・オフラインでも使用可能
・高い自由度で本格的な制作ができる
●デメリット
・GPU搭載PCなど、ある程度のスペックが必要
・初期の環境構築に手間がかかる
・設定やトラブル対応に知識が求められる
・PCの性能によって生成速度が左右される
❷ Webサービス(クラウド)で使う
Stable DiffusionをAPIやライブラリとして使う方法は、画像生成機能をアプリケーションや業務システムに組み込める点が特徴です。プログラムから自動で画像生成を行えるため、バッチ処理や大量生成、他システムとの連携に適しています。導入や運用には技術的な知識が求められます。業務効率化やシステム連携を重視する場合に適した使い方です。



コメント